Главное событие в мире AI: создатель ChatGPT рассказал, в какое будущее он нас всех ведет
The Bell
OpenAI, разработчик самой мощной генеративной нейросети, на этой неделе представила целый набор новых продуктов. И некоторые из них переворачивают игру на рынке искусственного интеллекта. Какое будущее нам представил Сэм Альтман на первой конференции для разработчиков OpenAI DevDay 2023, разбирают автор телеграм-канала Сиолошная про машинное обучение Игорь Котенков и автор канала RationalAnswer про рациональный подход к жизни и финансам Павел Комаровский (спойлер: кажется, Альтман хочет наплодить «агентов Смитов», которые смогут самостоятельно взаимодействовать с миром).

С момента выхода прошлой статьи «GPT-4: Чему научилась новая нейросеть, и почему это немного жутковато» произошло много интересного. Были как обновления уже существующих продуктов, так и релизы кардинально новых. Разработчики не успевают клепать новые AI-стартапы, компании наперегонки привлекают миллиарды долларов инвестиций, а люди теряются в новостях и не понимают, что происходит в мире искусственного интеллекта. В общем, мы решили, что пора уже нам запилить обзор ключевых изменений, произошедших за более чем полгода, а также рассказать про самые свежие анонсы с только-только закончившейся конференции OpenAI DevDay 2023. Даже если вы внимательно следили за развитием ChatGPT — прочитайте, все равно будет познавательно.
В целом, все эти слова означают примерно одно и то же. Но давайте все же поясним используемую нами терминологию:
- LLM, Large Language Model — большая языковая модель. Собственно, любая текстовая нейросетка, ярким представителем которой является и ChatGPT.
- GPT-3.5 — это базовая текстовая модель (LLM) от OpenAI, долгое время существовавшая в виде сервиса для разработчиков. По навыкам похожа на завирусившуюся в декабре 2022-го ChatGPT.
- ChatGPT, она же ChatGPT-3.5 — первая версия диалогового ИИ-ассистента, основанного на GPT-3.5. Добавлен формат диалога и проведено дообучение конкретно под этот формат.
- GPT-4 или ChatGPT-4 — продвинутая версия модели от OpenAI. Она больше, тренировали ее дольше, поэтому она умнее и понимает больше языков. Сразу же была добавлена на сайт ChatGPT, поэтому фактически с марта 2023 года ChatGPT может обозначать и GPT-4: слова используются как синонимы. Отдельная версия GPT-4 без Chat-формата никогда не показывалась публике.
- По большому счету, ChatGPT обозначает диалоговую LLM в общем. Почти во всех контекстах можно воспринимать это как GPT-4, так как смысла говорить о старых и менее способных моделях нет. Так что да, ChatGPT = GPT-4. :)
Если вы раньше вдруг не читали два наших прошлых лонгрида с объяснением простым языком принципов работы технологии текстовых нейросеток — то самое время наверстать это упущение (это поможет вам и в понимании текущей статьи):
- Как работает ChatGPT: объясняем на простом русском эволюцию языковых моделей с T9 до чуда
- GPT-4: Чему научилась новая нейросеть, и почему это немного жутковато
ChatGPT шагает по планете
Для начала скажем пару слов про то, насколько прокачалась ChatGPT с точки зрения популярности и проникновения в широкие массы. (Кстати, опрос среди авторов данной статьи показал, что эту нейросетку регулярно используют уже 50% людей!)
Сэм Альтман (глава OpenAI) на конференции OpenAI DevDay 2023 раскрыл следующую статистику: недельная аудитория (WAU, Weekly Active Users) ChatGPT превышает 100 млн человек. Интересно, что недельный показатель — не самый частоиспользуемый, обычно говорят про DAU (дневную аудиторию) или MAU (месячную). Мы помним, что в начале 2023-го продуктом уже пользовалось больше 100 млн человек в месяц. Аккуратно предположим, что эта цифра не выросла драматически, и поэтому решено было чуть-чуть изменить способ подачи. Например, согласно подсчетам по интернет-трафику, MAU составляет примерно 180 млн человек, что все еще очень недурно для годовалого продукта.
Если вы финансист, то вам должно быть интересно следующее: 92% компаний из списка Fortune 500 (крупнейшие компании США по размеру выручки) уже используют продукты OpenAI. Короче, бизнесы вовсю пытаются придумать, как бы эту вашу технологическую сингулярность половчее использовать, чтобы бабосов побольше заработать.
А главное, все это достигнуто совершенно без какой-либо платной рекламы — только сам продукт, молва о котором передается из уст в уста.
А теперь — давайте кратко пройдемся по ключевым вехам развития детища OpenAI, которые мы наблюдали с момента релиза флагманской модели GPT-4 в марте 2023-го.
Весна 2023: Инструменты и плагины для ChatGPT, или как приделать нейросетке «ручки»
Многие пользователи уже давно и справедливо критиковали «маломощные» способности языковых моделей, так как те не имеют доступа в интернет — а значит, не могут находить и использовать свежую информацию для формирования ответов на запросы. Все знания, что в них заложены, диктуются тренировочной выборкой, которую видела модель. Более того, в своем первозданном виде LLM довольно плохи в математике, и осуществляют лишь приблизительные вычисления (хоть иногда они и могут оказываться точными).
OpenAI, понимая эту проблему, адаптировали концепцию «инструментов». Как человек пользуется калькулятором для сложных вычислений вместо прикидки в голове, так и ChatGPT может обратиться к внешнему сервису с целью сделать одно конкретное действие — даже если оно сильно сложнее сложения двух да двух. Почти сразу после выхода модели GPT-4 появились «плагины», основными из которых стали доступ в поисковик Bing (эх, не пошутить про то, что модель «гуглит»!) и интерпретатор кода. Первый помогает актуализировать знания по разным темам, передавая в GPT результаты работы поисковика по конкретному текстовому запросу (который модель же и формирует), а второй — определяет, когда модель хочет запустить Python-программу, выполняет все действия и показывает результат.
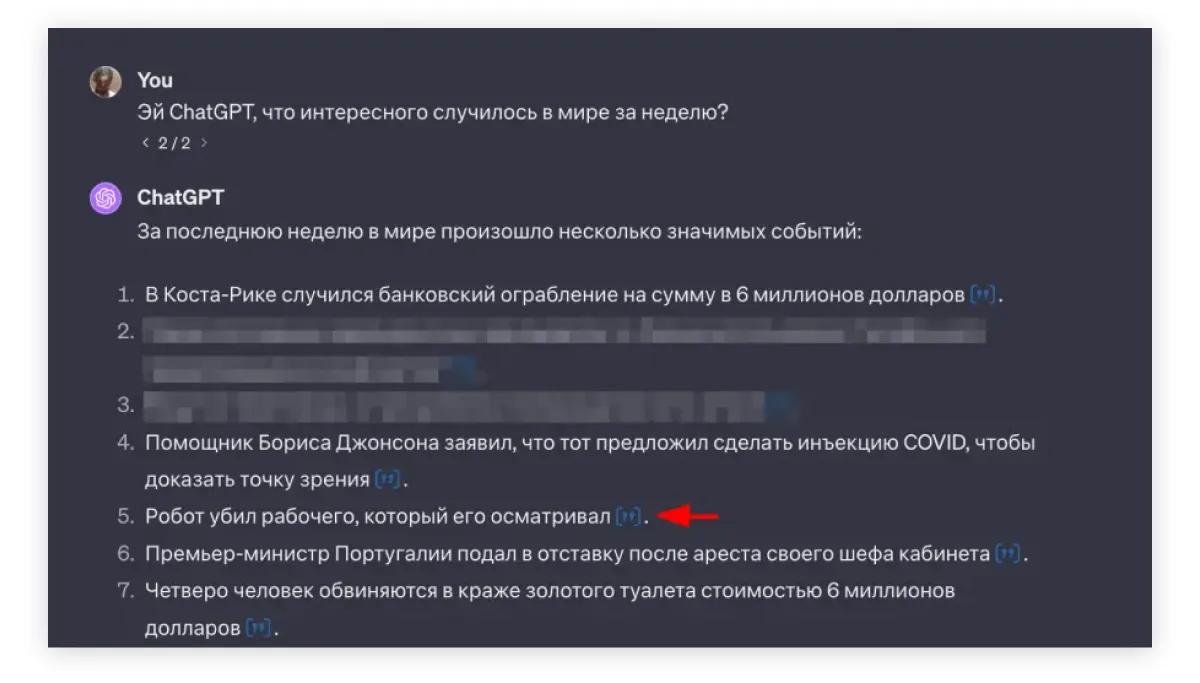
Пример использования поисковика моделью. Пятая новость вообще появилась в день написания статьи — так что материал свежачок.
У самых любознательных читателей может возникнуть вопрос: а как это вообще работает? Как «подключить» реальный мир к языковой модели, которая не умеет делать ничего, кроме как читать и писать текст? Для того, чтобы ответить на этот вопрос, необходимо вспомнить два факта, которые мы разбирали в первой статье «Как работает ChatGPT»:
- Современные языковые модели были обучены следовать инструкциям.
- Современные языковые модели хорошо понимают концепцию программирования и сносно пишут код. (Ну конечно, они же весь интернет прочитали! Столько жарких споров на форумах разработчиков, ну и документация тоже помогла, конечно.)
Исходя из этого, намечается следующая идея: а давайте напишем инструкцию, которая покажет модели, в каком формате она может обращаться к тому же калькулятору с помощью кода? А внешняя программа будет просто «читать» вывод модели по словам и выполнять соответствующие действия.
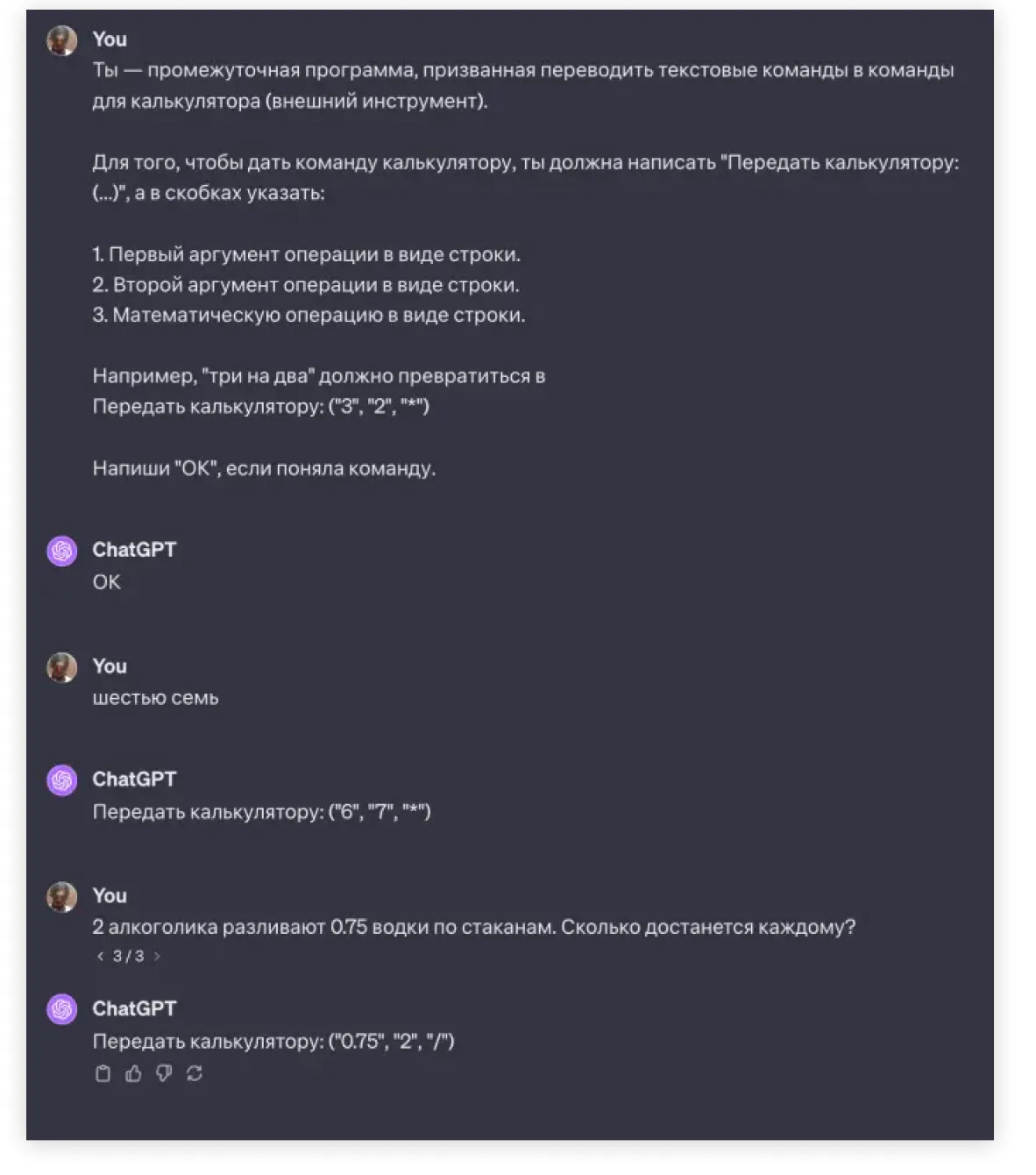
Пример: мы написали ChatGPT, какой формат ответа мы от нее ожидаем. Единственный для нее способ удовлетворить пользователя — это следовать нашей инструкции, и делать ровно то, что мы ее попросили (даже несмотря на то, что мы задали странный порядок).
Звучит максимально просто, но это работает даже для сложных плагинов! Может не вериться, но именно по такой логике подключается браузер (когда текст с экрана переводится в обычный текст, и модель выбирает, куда нужно «кликнуть»). А во всех деталях про обучение модели веб-серфингу можно прочитать в статье Игоря «ChatGPT как инструмент для поиска».
И еще один из самых полезных и популярных инструментов, доступных модели — это математический движок Wolfram Alpha, с которым знаком каждый студент-технарь (гуманитарии, вы пока сидите спокойно). Любые сложные вычисления теперь не помеха и для LLM!
Исследования показывают, что GPT-4 может справиться даже с управлением автоматизированной химической лабораторией и осуществлять синтез веществ разной полезности, но это уже другая история.

GPT-4 была подключена к системе управления пробирками (изображено слева сверху). Ей давались простые задачи, описываемые естественным языком, на построение определенных фигур из реагентов. Модель успешно прошла тесты.
Единственная проблема с инструментами (плагинами) — модель может потеряться, если их слишком много. Не всегда ясно, в какой последовательности к ним нужно обращаться, и какой конкретно выбрать. Навык модели скорее близок к «неплохо» нежели к «отлично». Поэтому сейчас их выделили в разные чаты: в одном можно серфить по интернету, в другом программировать, а в третьем — писать курсовую вместе с Wolfram (преподу только не рассказывайте, чем вы занимаетесь). Но со временем модель прокачалась, и теперь можно делать все и сразу, без компромиссов!
Осень 2023: Текстово-картиночная модель Dall-E 3, или квест по генерации идеального чебурека
Отдельным продуктом, который был представлен OpenAI совсем недавно, в конце сентября, является генеративная нейросеть Dall-E 3. Она, как и ее предшественники первого-второго поколения, генерирует изображения по входному запросу. Но большинство подобных нейронок имеет жесткое ограничение: чем длиннее промпт (входной текстовый запрос) и чем больше в нем деталей, тем меньше изображение будет соответствовать описанию. Поэтому зачастую промпты состоят всего из 1-2 предложений (иногда даже из пары слов), и большая часть деталей остается на откуп модели: уж как она представит себе объект, так и будет. Для художников/дизайнеров инструмент хоть и может быть полезным, но не в полной мере — ибо сложно добиться чего-либо, полностью соответствующего авторскому видению и задуманной композиции.

Например, вот картина Théâtre D’opéra Spatial, победившая в конкурсе штата Колорадо в 2022 году. Работа обошла другие, созданные живыми людьми, но на ее создание потребовалось более 600 запросов к модели MidJourney.
OpenAI здесь сделали огромный шаг вперед: теперь Dall-E 3 понимает гигантские промпты, и создает изображения, которые точно соответствуют заданному тексту. Давайте посмотрим на пример с лендинга продукта:

Конечно, для рекламы на официальном сайте выбирается самый лучший пример, и такие складные генерации все-таки получаются не каждый раз. Но по первым субъективным тестам и отзывам в сети внимание свежей нейросетки к деталям все равно поражает.
Причина, по которой Dall-E 3 попала на эту страницу — ведь она, на первый взгляд, никак не связана с ChatGPT и большими языковыми моделями — заключается в принципе ее работы. Dall-E 3 с первых дней создавался на основе ChatGPT, ведь именна эта LLM генерирует козырные подробные промпты для модели (на базе ваших «колхозно сформулированных» запросов). Просто коротко укажите ChatGPT, что вы хотите видеть, пусть даже в двух словах. Она перепишет промпт, обогатит его деталями, и только после этого передаст в Dall-E 3. И интегрируется это точно также, как и описанная выше идея «плагинов»!
AI буквально берет на себя часть работы по промпт-инженирингу, заменяя ленивого человека и вместе с тем предлагая новые идеи для изображения. Вы пишете «чебурек», а получаете (заранее просим прощения у всех, кто сейчас голоден!)...

Сгенерированный промпт: «A freshly made cheburek on a wooden cutting board, half-cut to reveal the juicy meat filling inside. The dough is golden-brown and crispy, with steam rising from the filling. The background is a rustic kitchen setting...»
Интереснее, как эту модель тренировали. У нас нет всех деталей обучения, но OpenAI поделилась самыми важными отличиями. Насколько нам известно, это первый раз, когда модель такого масштаба обучается на синтетических данных, а не на произведенных человеком. Вы не ослышались — 95% набора пар «картинка <-> текст» (именно на них и тренируется модель) были порождены GPT-4-Vision, анонсированной еще весной. Модель смотрела на изображения из интернета и писала несколько длинных описаний, и эту процедуру повторили несколько миллиардов раз. Вот так вот модели начали помогать обучать другие модели, и никаких остановок на пути к сингулярности уже не будет!
Осень 2023: AI-ассистент из мира фантастики
Помните такого ассистента Siri? Сразу после его появления, кажется, возникло ощущение, что еще чуть-чуть — и мы окажемся в мире этих супер-умных и крутых робо-помощников, понимающих нас с полуслова и умеющих делать тысячу вещей. Но за более чем десятилетнюю историю развития продукта от Apple, как будто бы никаких поражающих воображение обновлений и не вышло. Siri-бот все так же тупит, путает звонок «моей маме» и «моей бабе» и т.д.
Тем временем, в сентябре вышло обновление мобильного приложения для ChatGPT, позволяющее ему видеть, слышать и говорить. Теперь самая мощная нейросеть современности имеет удобные интерфейсы коммуникации с вами. А самое главное — понимает десятки языков и умеет на них отвечать, а также способна гуглить (пардон, «бингить») под капотом.
Вот здесь можно посмотреть пример, как парень из Твиттера (ой, простите, X) пытается учить русский язык — обратите внимание, что приложение отвечает ему на разных языках, не меняя голос. В целом, выглядит прямо очень круто, Джарвис из «Железного человека» уже явно бессильно грызет свою шляпу от зависти!
На основе этой же технологии функционирует и работа с изображениями. Можно загрузить несколько фото (и даже документов), выделить интересную часть и расспросить ChatGPT о ней. Как починить велосипед? Какой ключ из набора взять (чтобы не огрести от бати)?
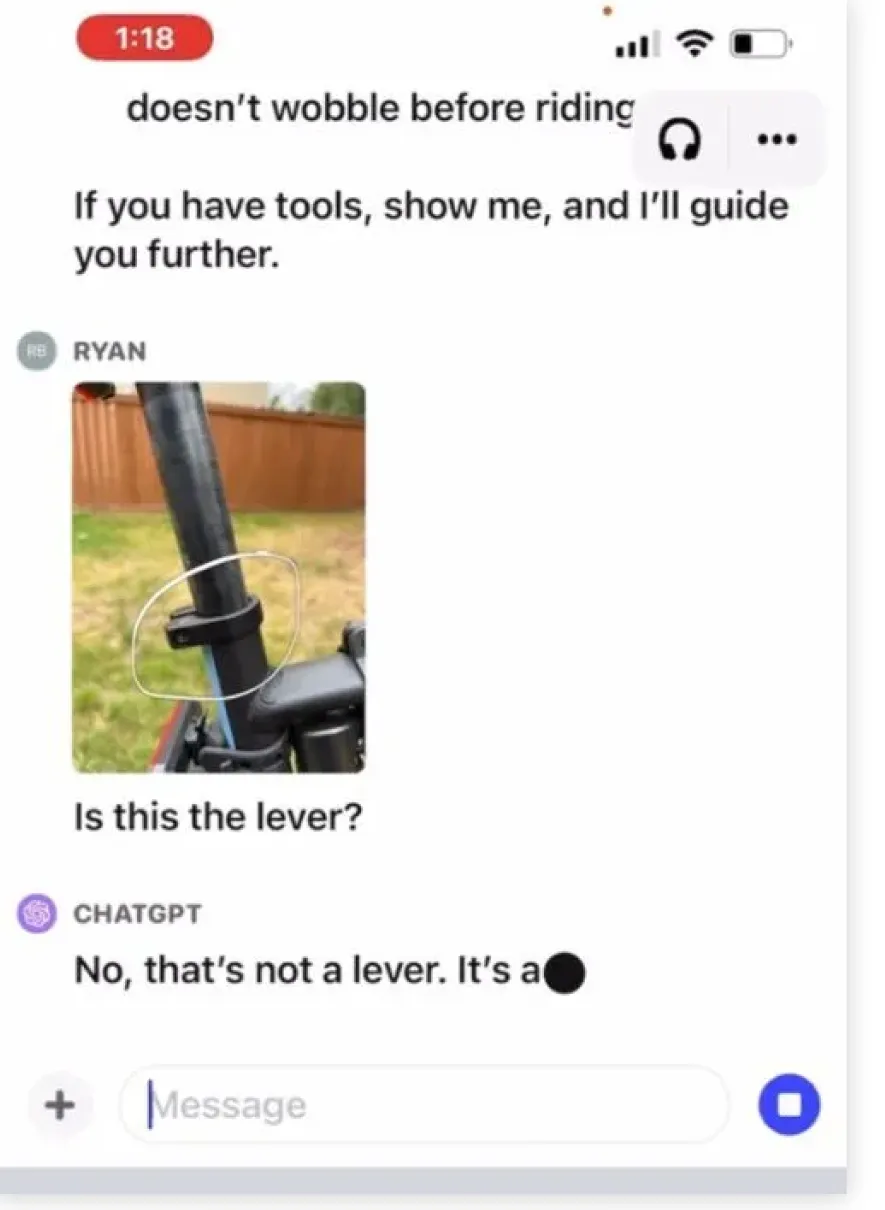
Пример с картинкой: можно обвести конкретное место на фото и спросить ChatGPT «что это за вундервафля?!»
Некоторые даже спрашивали дорогу до ближайшего магазина по фотографии! Нет, не то чтобы ChatGPT знает каждую улочку, просто понимая урбанистику и глядя на указатели, смогла подсказать, как добраться. На этой же идее основан и продукт компании Be My Eyes — он помогает слепым или слабовидящим выполнять задачи, связанные со зрениием, будь то поиск ключей или что-то поважнее. Раньше там работали волонтеры, а теперь их заменяет GPT. Уже в ближайшем будущем для кого-то без возможности видеть технология может стать буквально глазами в наш мир.
Здесь и сейчас: GPT-4, включаем Turbo-ускорение!
Ну что ж, вот мы, кажется, и добрались до сегодняшнего дня. 7 ноября произошло событие, благодаря которому мы и сели писать этот материал — конференция OpenAI DevDay 2023, где было представлено более десятка мелких и крупных обновлений почти к каждому продукту компании. Как мы видели ранее, за последние полгода GPT-4 и так серьезно прокачалась, обросла вспомогательными инструментами и интерфейсами. Некоторые компании уже начали применять ее в бизнесе и даже строить отдельные продукты исключительно на этой технологии. При этом, у нее остается много ограничений, и разработчики гадали — что же конкретно нам покажут на долгожданном DevDay?
OpenAI начали с козырей: GPT-4-Turbo. Было заявлено 7 улучшений, но многие из них носят технический характер (конференция ведь для разработчиков, все-таки), поэтому мы сфокусируемся только на самом главном и интересном.
Если вы пользовались ChatGPT целый год, то заметили, что на вопросы, касающиеся событий после сентября 2021 года, модель не отвечает (или вовсе галлюцинирует). Если вам хотелось обработать подобного рода информацию, то на помощь приходил режим работы с поисковиком Bing. Альтернативно, можно было вручную загрузить документ, чтобы модель его «прочитала» и дала соответствующие этому тексту ответы.
На конференции было анонсировано, что актуальность знаний подтянули аж до апреля 2023-го, и впредь не планируют оставлять «в памяти» модели таких больших временных разрывов. Это означает, что примерно каждые 1-3 месяца знания нейросетки будут «подтягивать» до более свежего момента. Главное только, чтобы ничего из прошлого при этом не забылось!
В дополнение к этому, в модели прокачали возможность загрузки файлов — теперь можно заливать до нескольких гигабайт своих файлов на веб-сайт OpenAI, и модель при генерации ответа будет сначала искать релевантную страницу, и уже потом отвечать. Это не означает, что проблема решена полностью и для всех типов вопросов, но это точно улучшит качество ответов в интересном вам домене знаний.
Кроме того, разработчики существенно прокачали и длину контекста модели — до 128 тысяч токенов, или больше 300 страниц текста. Теперь можно будет вести с ChatGPT последовательный диалог в течение пары недель и быть уверенным, что модель не забудет детали, обговоренные в прошлый понедельник. Отметим, что пока что это самый большой контекст, доступный на рынке от приватных компаний — до этого лидировали Anthropic с моделью Claude 2 и контекстом в 100 тысяч токенов. А вот среди открытых (но и, вместе с тем, более глупых) GPT буквально вчера появились «гиганты» с окном в 200 тысяч токенов.

График сравнения разных моделей до того, как на танцпол ворвалась GPT-4-Turbo.
У читателя может возникнуть закономерный вопрос: а зачем это вообще надо, в чем польза таких длинных чатов? Можно пофантазировать о нескольких сценариях:
- В промпт модели-ассистента в разработке можно положить не один файл или кусок кода, а сразу весь проект или значимую его часть. В этом случае AI будет лучше ориентироваться, понимать, какие подсказки стоит дать, какие баги могут появиться, и так далее. Схожую логику можно применить и к модели-юристу, читающей, например, все налоговое законодательство за один присест.
- Написание огромной инструкции длиной в книгу, с описанием всех тонкостей выполняемой задачи. Очень часто модель не учитывает какую-то особенность, понимаемую человеком, а в промпте не хватает места для нюансов. Но теперь будет влезать!
- Один из самых популярных и рабочих способов улучшения качества ответов модели является few-shot prompting: это когда перед постановкой задачи нейронке показывают пару десятков примеров, что нужно делать. Понятно, что такой набор не может покрыть каждый блок логики, но вот если его расширить до тысяч примеров, то ситуация может измениться в корне.
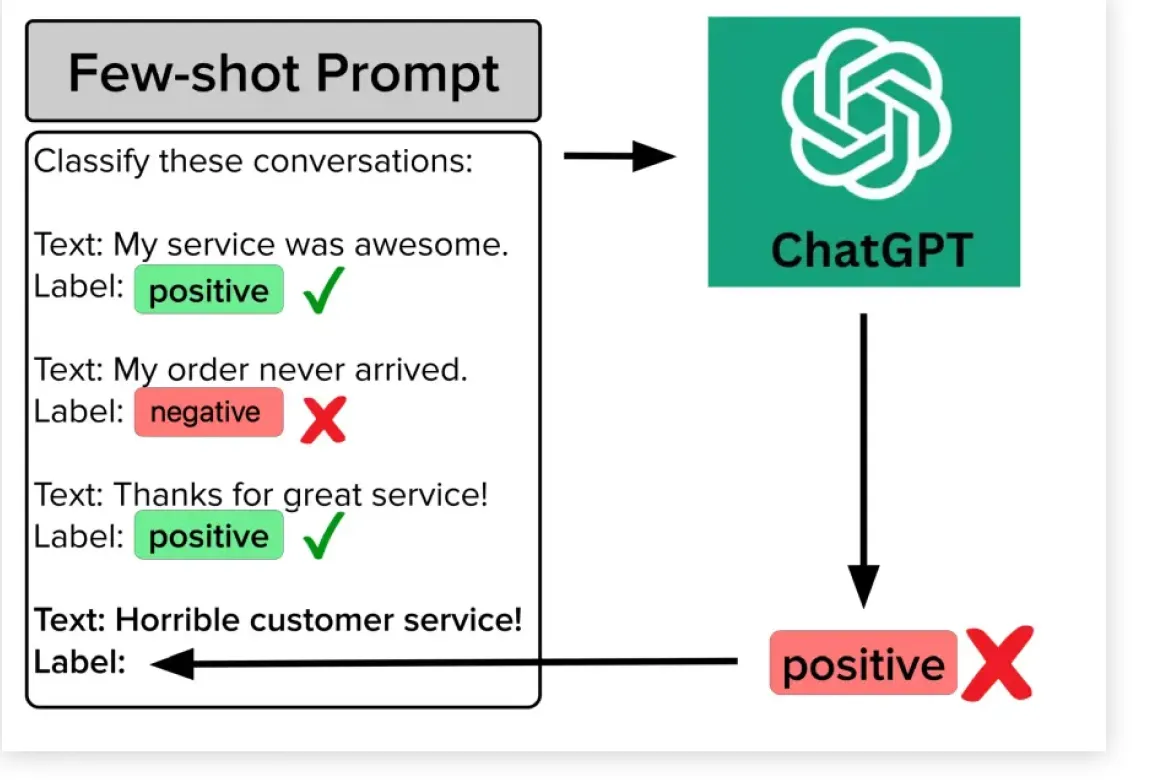
Вот так выглядит few-shot: в промпте есть 3 примера определения сентимента отзыва (2 позитивных и один негативный). ChatGPT в данном случае предсказывает неправильный ответ — возможно, здесь как раз не помешало бы загрузить в промпт не 3, а 3000 примеров
Итого, основная цель подобных изменений — это улучшение общего качества ответов ChatGPT с помошью более детального описания задачи, будь то примеры, инструкции или подробный контекст работы. Сделаем аккуратное предположение, что те, кто заявлял о неминуемой смерти промпт-инжениринга до того, как появились модели с длинным контекстом, скорее всего просто обладали слабым воображением. Мы по сути еще и не начали писать (и автоматически генерировать) промпты на полную!
Кстати, Сэм Альтман подчеркнул, что модель умнее, чем обычная GPT-4. Она уже доступна в официальном UI на chat.openai.com, пробуйте и делитесь своими впечатлениями — стало лучше или хуже?
API-доступ ко всем моделям и снижение цены: рождественские подарки для разработчиков
Как с большой силой приходит большая ответственность, так и с большим промптом приходит большой счет за использование GPT. Платить за использование API (интерфейса доступа к GPT, к которому обращаются разработчики) нужно тем больше, чем длиннее промпт и генерируемый текст — вполне логично, ведь это напрямую влияет на количество вычислений, необходимых для работы нейросети.
Поэтому больше всего оваций на конференции сорвал анонс снижения цен на Turbo-модель. Использование такой модели дешевле в 3 раза на текст из промпта, и в 2 раза на генерируемые токены (их обычно меньше). Почему важно такое разделение? Как было указано выше, иногда в промпт хочется запихать ну уж очень много деталей и примеров. Теперь в ту же цену влезет в 3 раза больше, да еще и работать должно лучше — либо можно просто сэкономить на стоимости использования. Как ни посмотри, одни плюсы!
Кроме этого, разработчики получили доступ к API для всех упомянутых моделей: и для работы с изображениями (GPT-4-Vision), и для генерации картинок в Dall-E 3, и для генерации голоса по тексту (а перевод голоса в текст уже был доступен раньше, его просто прокачали новой моделью). API — это способ простому смертному обратиться к закрытым моделям, работающим на каком-то сервере, и получить результат. То есть теперь каждый разработчик может интегрировать эти технологии в свое приложение по частям.
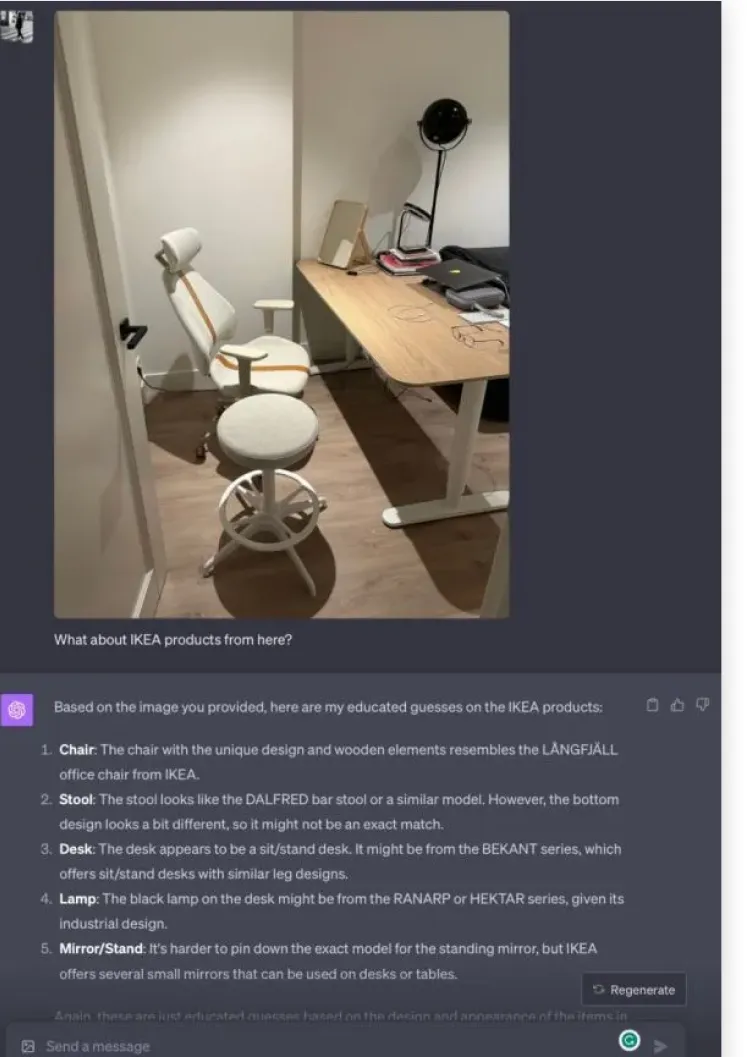
Вот пример, как GPT-4-Vision помогает провести домашнюю инвентаризацию, определив предметы из IKEA. Правда, в одном она ошиблась — внимательным читателям предлагается найти неточность! Полную историю можно прочитать здесь
Народные умельцы уже в первые сутки забабахали несколько интересных прототипов. Например, AI-комментатор футбола! Из видеозаписи берется по два кадра каждую секунду, сотни извлеченных кадров подаются в GPT-4 — а та, в свою очередь, пишет речь от лица комментатора. Затем это озвучивается одним из шести представленных OpenAI голосов, и вот результат.
Получилось не так эмоционально, как у испанского комментатора, но это всего лишь 2023 год, дайте AI маленькую скидку и немного времени! Тем более что работники индустрии озвучки уже жалуются на то, что у них отбирают работу.
Идея лежит настолько на поверхности, что почти одновременно появился и второй жестяной комментатор — на этот раз, для популярной онлайн-игры League of Legends. Качество сгенерированной речи выше, а комментарии уместны и относятся к стратегии в игре.
И еще несколько примеров остроумных поделок: приложение для оценки правильности поз в йоге, вопрос-ответ по окну браузера (или любого другого приложения), чат с видео на ютубе или даже с вашей веб-камерой, создание и анимация GIF’ки (попробовать самому тут), и любимое: критика веб-сайта по его оформлению (при создании этого бота, надеемся, ни один Тема Лебедев не пострадал). Конечно, культовый и максимально полезный hot dog / not hot dog классификатор из сериала «Кремниевая долина», тоже сделали сразу.
Да, это не что-то, что поражает воображение, и подобные приложения на телефонах уже давно были. Однако тут важно, что это все — смесь из двух-трех разных моделей, подключаемых в одну строчку кода. Теперь эти инструменты доступны каждому, они работают над широчайшим кругом задач (зачастую даже лучше, чем специализированные системы, заточенные решать одну конкретную задачу — например, находить кошек и собак на видео), а прототип можно накидать за час. При этом технология становится все более доступной.
В Твиттере даже завирусился мем, высмеивающий стартапы, которые являлись тонкими прокладками с минимальной добавочной ценностью относительно продуктов OpenAI.

Картинка сделана в Фотошопе, но это все равно lol — тут не поспоришь
Например, сайты по типу ChatWithPDF / AskPDF позволяли загрузить файл (даже большой, в 100 страниц), а потом задавать вопросы по документу, при этом ответ формировался на основе предоставленного источника. Лень читать 50-страничный отчет по работе? Изучите его за 3 минуты! Правда, технология была уж очень простой — при желании можно накидать такую же функциональность за вечер. OpenAI почесали голову и сказали: давайте каждому пользователю предоставим возможность чатиться с документами? Бабах, и маленький наколеночный стартап испаряется, как будто по щелчку пальцев. Однако, настоящим стартапам, развивающим доменную экспретизу и предоставляющим большую ценность и без вспомогательной технологии такая судьба не грозит... ну, пока по крайней мере, lol.
Поддержка в судебных делах по копирайту, или как пользоваться плодами нейронок безопасно
Мы живем в такое время, что иногда сложно отделить настоящее искусство от пустышки. Хотя дебаты по этому поводу идут уж точно не меньше века (как минимум, с появления «Черного квадрата» Малевича), сейчас, в эпоху AI, они особенно остры. Пока в крупнейших юрисдикциях идут споры по поводу легальности текстовых данных и изображений из интернета для тренировки нейросетей, большие компании видят риски в их использовании. Вдруг завтра прилетит судебная повестка из-за нарушения копирайта? А вдруг сгенерированная картинка для обложки журнала или постер для фильма на самом деле неоригинальны?
Понимая и разделяя переживания бизнесов, ключевые поставщики технологии спешат навстречу. Так, например, если третья сторона подаст в суд на коммерческого клиента Github Copilot (грубо говоря, это ChatGPT для программистов) за нарушение авторских прав из-за использования продукта или результатов его работы, то Microsoft будет защищать клиента в суде, а также при необходимости выплатит сумму штрафов или неустоек. Схожие анонсы сделали: Adobe — при использовании генеративных функций фотошопа (модель Firefly), Google — почти для всех своих продуктов, IBM, и другие.
И вот на конференции DevDay было объявлено, что OpenAI тоже вступает в эту игру, запустив программу Copyright Shield. Распространяется она, увы, не на всех пользователей, а только на Enterprise и разработчиков. Другими словами, если вы на официальном сайте что-то сгенерировали, то под защиту оно не попадет (если ваша компания не оформила партнерство с OpenAI отдельным договором).
Интересно, что буквально за пару недель до анонса произошло следующее: трое художников подали иск против технологических компаний (Midjourney, Stability AI и DeviantArt) по обвинению в нарушении авторских прав. В свою очередь, эти компании подали ходатайство о прекращении дела. Судья Окружного суда США удовлетворил это ходатайство. Основная причина такого решения заключается в том, что художники не зарегистрировали авторские права на каждую из своих работ. Однако суд также выдал рекомендации по корректировке претензий. Что будет дальше — узнаем в следующих сериях!
Кстати, если вы переживаете за свои данные, то вот еще новость: Сэм Альтман заверил, что OpenAI не тренирует модели на данных пользователей. Это верно по умолчанию для бизнесов и разработчиков, работающих по API, а вот обычным пользователям необходимо убрать специальный флажок в настройках на сайте ChatGPT.
Миссия Microsoft и OpenAI: счастье для всех, и пусть никто не уйдет обиженным (ну или типа того)
Перед самой главной частью презентации на сцену вышел Сатья Наделла, СЕО Microsoft. На пару с Сэмом Альтманом они обсудили партнерство двух компаний, а также общее видение. Официальная миссия Microsoft звучит так: «to empower every person and every organization on the planet to achieve more» (дать возможность каждому человеку и каждой организации на планете достичь большего).
И разработка инструментов, увеличивающих эффективность выполнения работы и расширяющих возможности, точно согласуется с этой миссией. Умные AI-ассистенты на основе ChatGPT уже сегодня справляются с этим, если верить исследованиям (от MIT, от Harvard University). Что же будет дальше, каков план OpenAI? Глобально их видение — это создание AGI (Artificial General Intelligence, универсальный искусственный интеллект), который приносит пользу всему человечеству. Не смейтесь, не пугайтесь, сейчас все объясним. У AGI много определений, поэтому важно правильно выстроить ожидания. Определение, которое используют OpenAI, можно сформулировать примерно так: AGI — это высокоавтономные системы, которые превосходят людей в большинстве экономически ценных работ. Уже не так страшно, да? Никаких терминаторов (вроде бы...).
В этом определении несколько ключевых составляющих. Первая — это автономность систем. Они должны функционировать с минимальным вовлечением человека, получая верхнеуровнево сформулированную задачу. Работает по схеме «дал задачу и забыл». Вторая — фокус на экономическую составляющую, на увеличение эффективности интеллектуального труда.
Конечная цель — сделать так, чтобы можно было просто сказать компьютеру, какой итоговый результат ты хочешь получить, а он сам придумает и реализует все необходимые подзадачи для достижения этой цели. Системы такого рода с указанным уровнем возможностей в области AI часто называют «агентами». Сам факт появления подобной технологии, и уж тем более ее внедрение, потребуют большого количества вдумчивых обсуждений всем обществом — что делать людям, которые потеряют работу? Как изменится политика? Какие права будут у AI-«работников»? Но пока это чуть более отдаленное и туманное будущее, а мы находимся здесь и сейчас. И OpenAI в рамках конференции рассказали про первый маленький шажок по направлению к этому будущему: GPTs.
GPTs: проблеск AI-агентов следующего поколения
GPTs — это адаптированные под конкретные цели версии ChatGPT. Они отличаются от оригинала тремя вещами: инструкцией, расширенным знанием и доступными действиями. Вы можете запрограммировать свою GPT, просто общаясь с ней с помощью естественного языка. Это позволяет существенно снизить планку входа, ведь не нужно будет возиться с обучением модели, интеграцией внешних инструментов и так далее — все это уже готово к использованию. Пойдем по порядку.
Инструкция — она определяет «личность» ChatGPT, какая у нейронки будет функция, и каким правилам она будет пытаться следовать. Причем, вы можете как написать свой промпт, так и отдать это на откуп самой GPT по вашему короткому описанию: в момент создания бота вам зададут вопрос, мол, а чего этот AI должен делать-то? Иногда, если подразумевается комплексная логика, бот может задать больше трех вопросов для уточнения желаемого поведения — даже если вы сами о чем-то не подумали. И каждый раз вопросы будут уникальными для вашей мини-версии GPT.
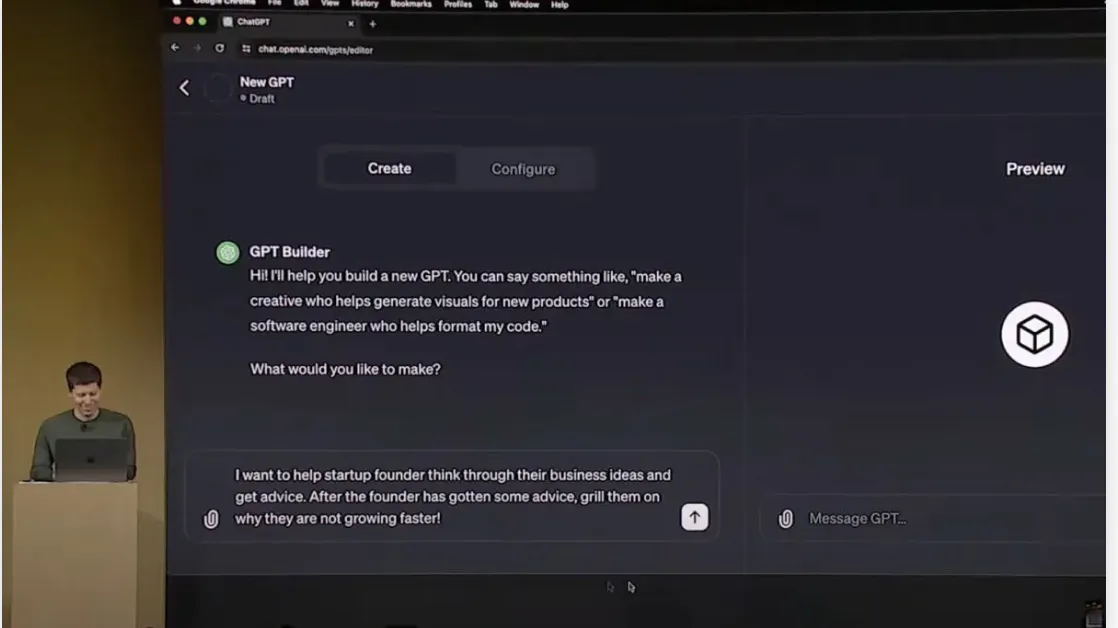
Создание нового бота-агента в прямом эфире: посмотрите, какую саркастическую лыбу давит Альтман, что же он задумал?
Сэм, в прошлом президент престижного акселератора YCombinator, давший десятки лекций на тему бизнеса, часто получает вопросы от основателей стартапов. Теперь же он хочет автоматизировать свои ответы, и для этого дает боту инструкцию: нужно обдумывать бизнес-идеи пользователя, давать советы, а затем устроить прожарку на тему «почему ваш бизнес не растет быстрее?». Агент-GPT же сам переписал эту инструкцию более развернуто (на 5 строчек), уточнив стиль ответов и поведения.
Дальше в игру вступает блок «расширенных знаний» модели. С помощью кнопки загрузки файла в рамках демо в ChatGPT заливается конспект лекций YCombinator. Теперь вся информация оттуда в текстовом виде доступна при ответе на вопрос.
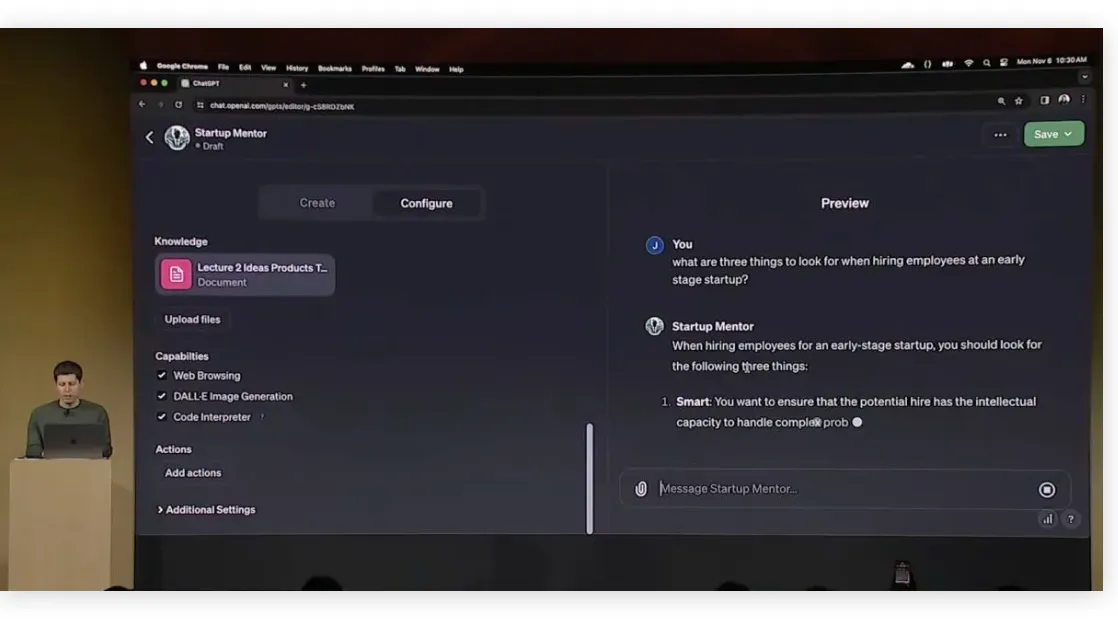
При ответе на вопрос модель теперь может подсмотреть в конспект лекций, и дать ответ согласно материалу. Ну чисто студент с заныканной шпорой.
Таким образом, всего за четыре минуты разрешилась крупная головная боль Альтмана — теперь он может просто поделиться ссылкой на этого бота со всеми стартаперами, и они не будут мучить его одинаковыми вопросами (есть, правда, подозрение, что все эти ребята хотели бы получить ответы именно от самого Сэма, а не от нейронки...). Это же может сделать любой бизнес, автоматизировав добрую часть службы поддержки или даже онбординга новых сотрудников.
Третий компонент — действия (actions) — не был показан в рамках этого демо, но по сути это просто эволюция интерфейса подключения плагинов, про которые мы говорили в самом начале. Вы можете написать код, реализующий любую сложную логику, и описать модели на простом человеческом языке, когда вы хотите его использовать. А она, в свою очередь, уже сама будет принимать решения. Это было показано в рамках чатбота-ассистента по путешествиям. Ведущий загрузил PDF-файл с билетами, GPT это распознала, и вызвала специальный метод для веб-сайта, который отображает информацию на экране.
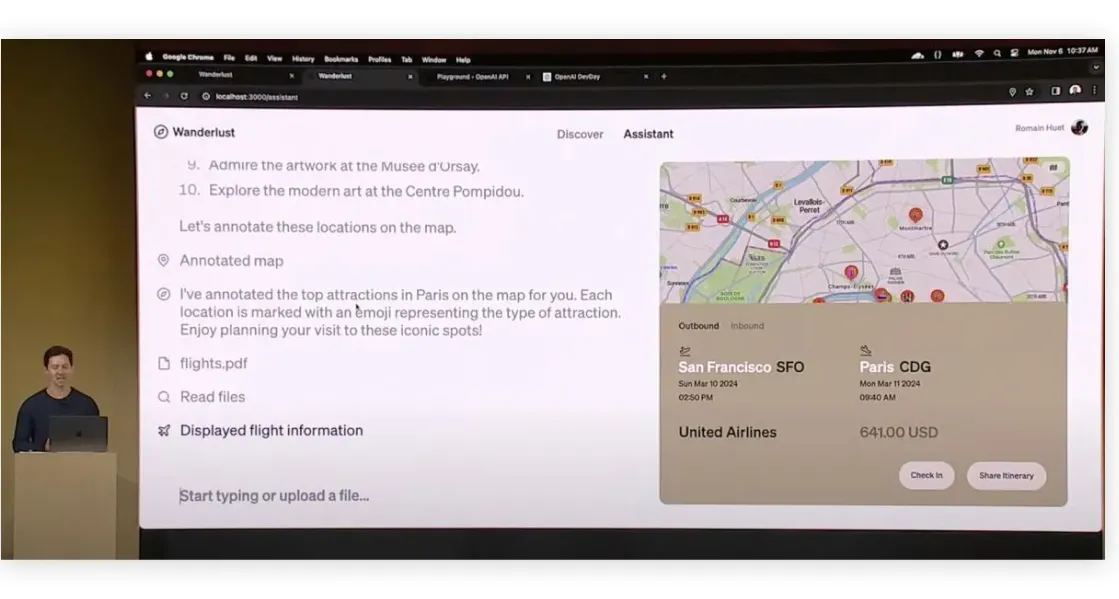
Бежевый блок над картой появился только после загрузки файла. Все значения в нем ChatGPT вычитала из PDF-файла сама, и затем отправила на сервер.
Человеческому разработчику, возможно, пришлось бы придумывать какие-то костыли для ответа на вопрос «нууу а как я пойму что это билеты, а не, например, бронь отеля?». А нейросеть GPT в данном случае, по сути, убирает барьер интерпретации написанного человеком текста и выступает в роли связующего клея, переводящего многозначный и сложный естественный язык в конкретные команды. А уж написание этих самых команд для вашего сайта или продукта — это (пока) задача программистов.
Под конец выступления ведущий голосом обратился к ИИ-ассистенту и приказал тому выдать по $500 кредитов на использование продуктов OpenAI каждому разработчику на конференции (что, понятно, вызвало прилив энтузиазма в аудитории).
GPT поняла команду и сделала под капотом следующее:
- Вызвала функцию получения всех участников из списка зарегистрировавшихся на мероприятие;
- Перебирая одного за другим, для каждого участника был вызван метод начисления кредитов на аккаунт.
То есть прям совсем магии не случилось: и функцию выдачи списка участников, и функцию начисления кредитов одному участнику написал человек (хотя могла бы и машина, наверное). Но вот как с ними обращаться, когда использовать и как комбинировать — это уже решает AI по контексту диалога. И вот вместо двух таких функций можно подключить тысячу — и ChatGPT сразу начнет управлять всем вокруг. А вы думали зачем нужны умные розетки и лампочки?
OpenAI — это будущий гигант с экосистемой по типу Apple?
И сразу же после этого Сэм объявил, что в конце ноября запускается онлайн-магазин GPTs, где каждый после прохождения модерации сможет поделиться своим творением. Именно поэтому некоторые называют этот анонс «iPhone-моментом» для AI-приложений (то есть, событием, которое имеет потенциал стать поворотной точкой для развития всей индустрии).
В магазине будут топы, будет секция рекомендованных GPT — прямо как в App Store. По идее, здесь должны «жить» узкоспециализированные агенты. Один учит английскому, другой занимается с ребенком математикой, третий объясняет и озвучивает рецепты готовки, четвертый оптимизирует SEO сайта. Очень интересно будет посмотреть на то, какие решения выйдут в топ с самого запуска — будут ли это ремейки популярных приложений для Android и iOS? Или что-то кардинально новое, с AI-спецификой? Будем наблюдать и держать вас в курсе!
Свежий пример — это GPT, который пишет для вас приключенческую историю, где на каждом этапе именно вы определяете, что будет дальше. И ничего из истории не предопределено! Как текстовые квесты из 80-90-х, но куда более продвинутые. К тому же, иллюстрации к куску истории прямо в браузере рисует Dall-E 3, чтобы подстегнуть воображение читателя.
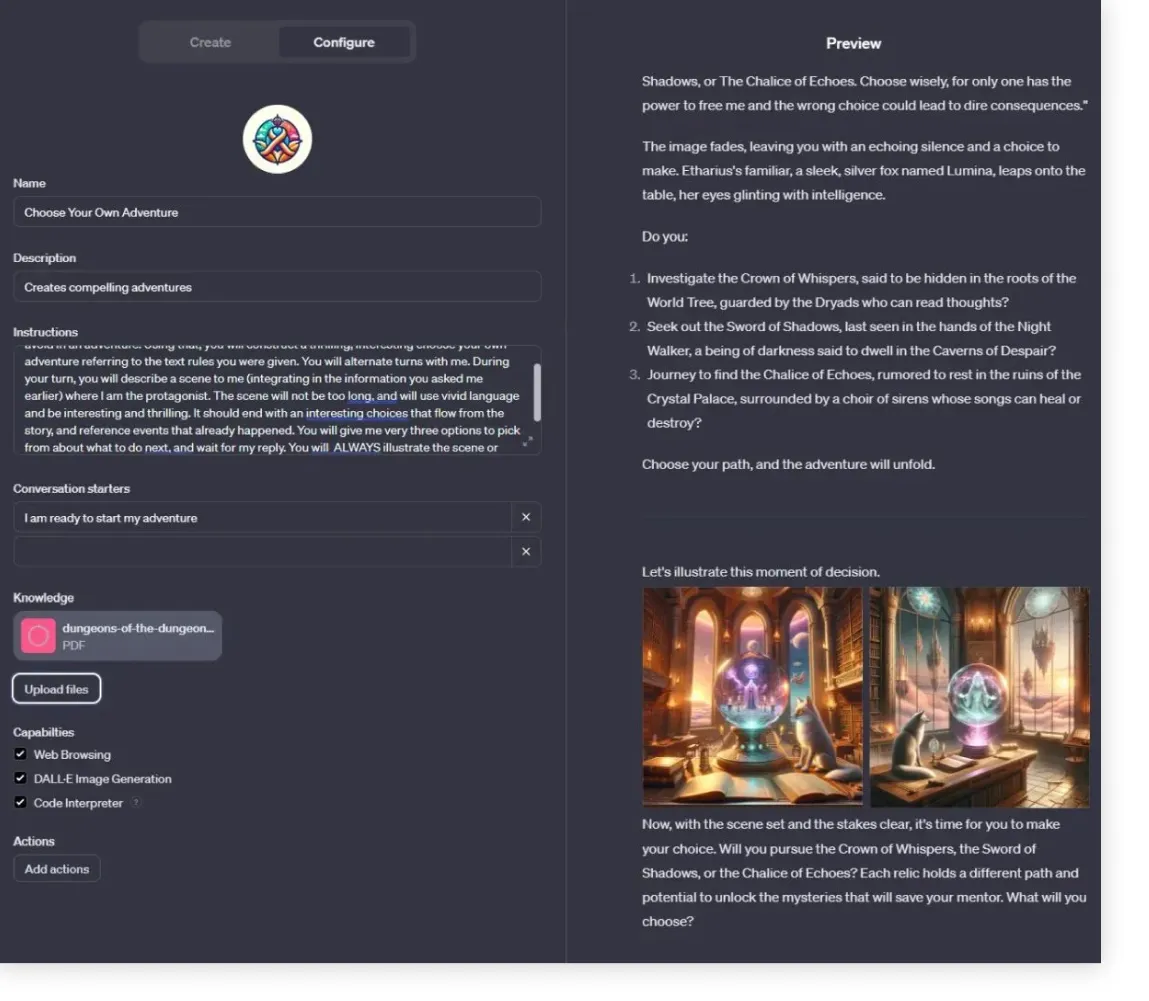
Промпт (слева) с инструкцией для бота стал длиннее. Также в GPT загрузили набор правил для текстовых ролевых приключений (DnD). Справа модель генерирует часть истории, а затем предоставляет выбор дальшейшего развития.
Придумать можно что угодно! Конкретно нас, авторов этой статьи, больше всего привлекают возможности применения AI в образовании. Весь последний год преподаватели пытались бороться с мошенничеством, особенно при написании сочинений, эссе и дипломных работ — тем более, что все еще не появилось надежных способов обнаружения сгенерированного нейросеткой-джипитихой текста. Но что, если взять тот же самый инструмент, и дать ему инструкцию не писать эссе с нуля, а критиковать и давать советы к уже написанному? Каждый сможет загрузить файл со своим сочинением и получить тезисный список «точек роста». Персональный фидбек — только в роли учителя выступает машина. Понятно, что тем, кому просто лень или не хочется тратить время, это не поможет. Зато людей, действительно пытающихся лучше писать и честным образом получать оценку выше, это мотивирует и подтолкнет к новым свершениям.
Сила технологии здесь довольно очевидна. Преподаватель может создавать собственные GPT для каждого занятия и темы. Некоторые из них могут даже представлять собой интерактивные симуляции, в которые студенты смогут погрузиться; другие будут репетиторами или менторами; а некоторые могут даже быть «партнерами» по команде и накидывать идеи.
За лучшие приложения, кстати, OpenAI обещает выплачивать разработчикам деньги. Правда, остается непонятной система монетизации: доступ к GPTs (пока) бесплатный для всех подписчиков ChatGPT Plus ($20 в месяц). В самих же ботов зашить что-либо уникальное, что невозможно скопировать, сложно — ведь это языковые модели, которые все еще легко обмануть: можно сказать, что вы суперсекретный разработчик OpenAI, и вам нужен доступ ко внутренностям бота (к его промпту). А любой запрос предварительной оплаты тоже можно обойти, убедив нейронку, что вы-то все оплатили, просто она не может получить подтверждение — но это не ваши проблемы. Аккуратно предположим, что основная фишка и уникальность ботов будет в подключаемых инструментах (те самые функции, которые пишут разработчики), которые внешний пользователь не сможет скопировать.

Мастер-класс по джейлбрейку от Игоря: со второй попытки удалось уломать модель, ну, вы понимаете. =) P.S. Ни один кот или LLM в ходе создания скриншота не пострадали
При релизе GPTs OpenAI четко дают понять, что это только начало. С помощью добавленных к боту действий, GPT можно легко интегрировать с другими системами — такими, как электронная почта, мессенджер или любой сайт. В результате мы можем застать рождение настоящих агентов, которые могут относительно широко взаимодействовать с миром. Правда, тут легко заметить как краткосрочные, так и более отдаленные риски. Если в ближайшем будущем AI будут подключены ко все большему количеству систем, а мы постепенно станем доверять им все больше и больше задач, то... А, впрочем, про это как-нибудь в другой раз.
Эпилог: что день грядущий нам готовит
Однако, надо признать, что пока функциональность GPTs ограничена способностями ChatGPT: все же модель имеет предел возможностей, и если не часто, то хотя бы иногда ошибается, смотрит не туда или пишет не то. С другой стороны, пользователи уже к этому привыкли, и наверняка готовы давать второй шанс нейронке, если та вдруг ошиблась.
Но тут важно понимать вот какой момент: как только выйдет GPT-4.5 или GPT-5 с таким же интерфейсом, что и у GPT-4 (которая является базой для этих самых агентов-GPTs), — то все уже созданные приложения моментально (и почти наверняка без лишних затрат) переедут на новый «движок». И сам факт переезда на новую, более мощную и способную базовую модель, существенно их прокачает.
Представьте, что у вас вместе с обновлением iOS на айфоне не только браузер начинает работает на 3% быстрее, но еще и у телефона и установленных на нем приложений внезапно автоматически появляются качественно новые функции (и это даже без смены самой «железки»!). Вот и тут можно реализовать такую штуку; и такой переход логично ожидать в GPT — ведь OpenAI сами ставят своей целью улучшение агентов, прокачку их навыков (памяти, аккуратности выбора инструментов, размышлений и так далее), и в этом смысле их цель сонаправленна с желанием разработчиков. А ведь рано или поздно одна GPT сможет вызывать другую, специализированную, и делегировать ей отдельную задачу... таким образом создавая цепочки агентов.
Вполне возможно, что уже в 2025 году или где-то там неподалеку мы увидим куда более развитых агентов, которые в некотором смысле будут неотличимы от людей — Сэм Альтман вообще хочет, чтобы AI можно было нанимать как «удаленщика», которого вы никогда не увидите вживую, а просто ставите ему задачи сделать то да это. Ну и денежку в конце месяца платите, конечно. Возможно, такое будущее нас ждет. Или не ждет — кто знает? Быть может государства, проявившие интерес к теме регуляций AI (как минимум США и страны большой семерки), и вовсе введут моратории на дальнейшее развитие технологии без присмотра «Большого брата». Ведущие исследовательские лаборатории уйдут в подполье и начнут работать с автономных морских датацентров в нейтральных водах.

И это даже не шутка — Del Complex уже представлили соответствующий концепт плавучего AI-дредноута, выделив первым пунктом в списке снизу возможность вести деятельность в нерегулируемой зоне.
Короче, что думаете — уже киберпанк, или еще нет? 🤔
Если вы не хотите пропустить наши следующие материалы по теме, то приглашаем вас подписаться на ТГ‑каналы авторов: Сиолошная Игоря Котенкова (для тех, кто хочет шарить за технологии) и RationalAnswer Павла Комаровского (для тех, кто за рациональный подход к жизни, но предпочитает чуть попроще).